I’ve spent a lot of time working on document understanding for products like automated order entry and so I’m always looking for new ways to evaluate the visual capabilities of LLMs. About a month ago, I stumbled across this post by Mark Humphries about Gemini 3 Pro’s impressive ability to transcribe historical texts. This seemed interesting enough to spend an evening building an app around (and I wanted to impress my girlfriend, who majors in anthropology and is interested in medieval medicine).
I had never worked with manuscripts before, but I wanted something special: documents without public translations. After some quick research, we found the Digital Scriptorium, which seemed to have what I needed.
For example: Sutro Collection MS 04, Medical recipes

While it's certainly possible this has been translated before, we couldn't locate one online.
Many of these manuscripts have dozens to hundreds of pages, which is too much for current models to handle well all at once. Even when the full document fits inside the context window, performance degrades as the length increases. To prevent this, my initial attempt processed each page in parallel and asked Gemini to translate directly. This worked decently, but it was inconsistent and difficult to tell if issues were due to incorrectly reading the characters or misunderstanding the meaning. My next iteration split the transcription into a separate step before the translation, which improved the quality but made another issue apparent: accurately interpreting the meaning of one page often requires context from the rest of the document. Missing context was the main culprit behind a lot of the poor translations, so I decided to adopt a hybrid approach. Each page is now transcribed in parallel, but all of the transcripts are concatenated for translation. Although this does bloat the context, the transcripts typically don’t consume nearly as many tokens as the raw images and this method was more reliable than my prior attempts.
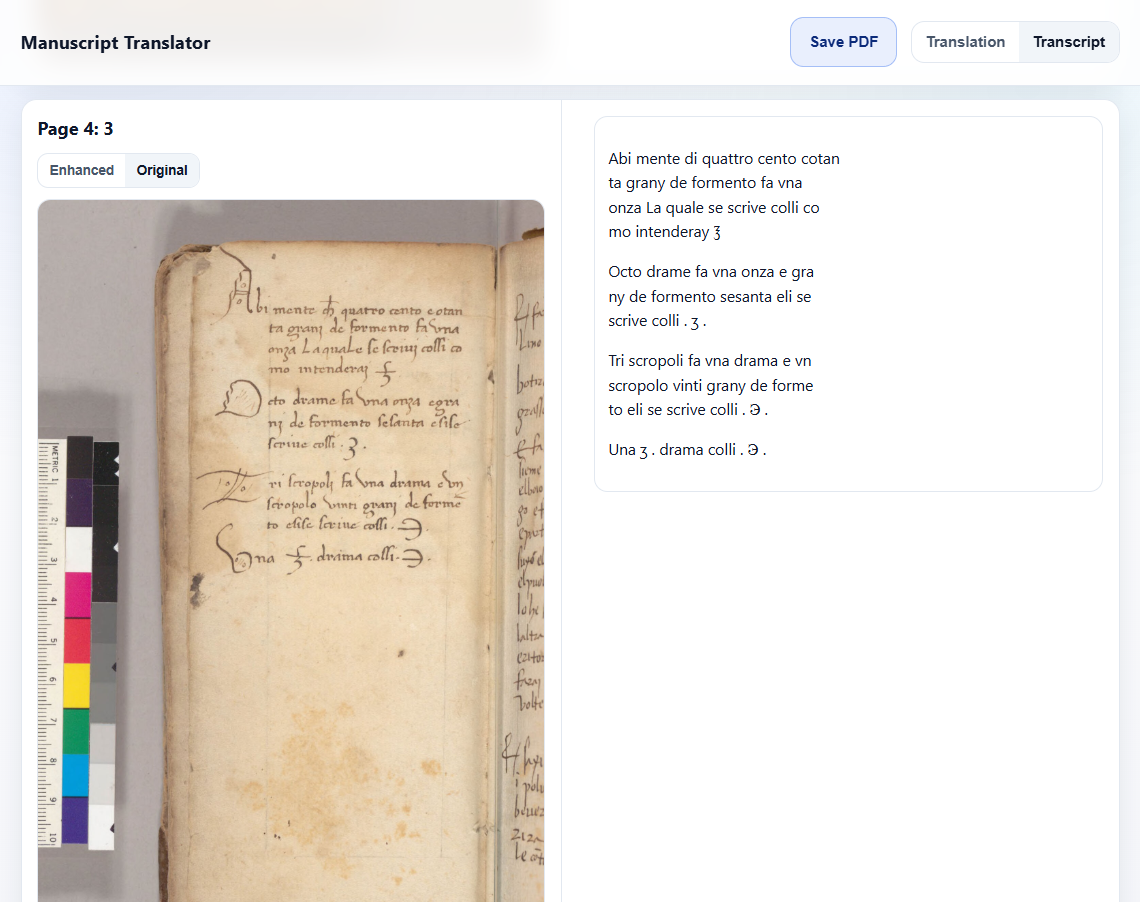
Transcribed page.
After testing both Gemini 3 Pro and Gemini 3 Flash, I went with the Flash model for transcription. It is much cheaper and faster (Pro sometimes cost dozens of cents per page), while still getting close to the same level of quality. To improve the consistency, the app samples multiple transcripts in parallel, then passes them all + the image back to Gemini to have it produce a final result.
The last problem was handling pages where the scans were taken from too far away. Although the images are typically very high resolution (e.g. 6000x4000), they are scaled down to a standard input shape by the model provider before processing. This causes a lot of the details to be lost for pages that are zoomed out. My solution was to add a preprocessing step which asks Gemini 3 Flash to output a bounding box around the main area of text, then cropping to that section.
Additionally, it runs a blended Sauvola filter, a sharpness filter, converts to the CIELAB color space, and applies CLAHE to the L channel. These filters aren’t strictly necessary, but they made it easier for me to read the text and slightly helped the model too. I won’t go into too much detail here, as image processing is not focus of this post, but the basic idea is that they separate the text from the background and even the lighting and contrast across the image.
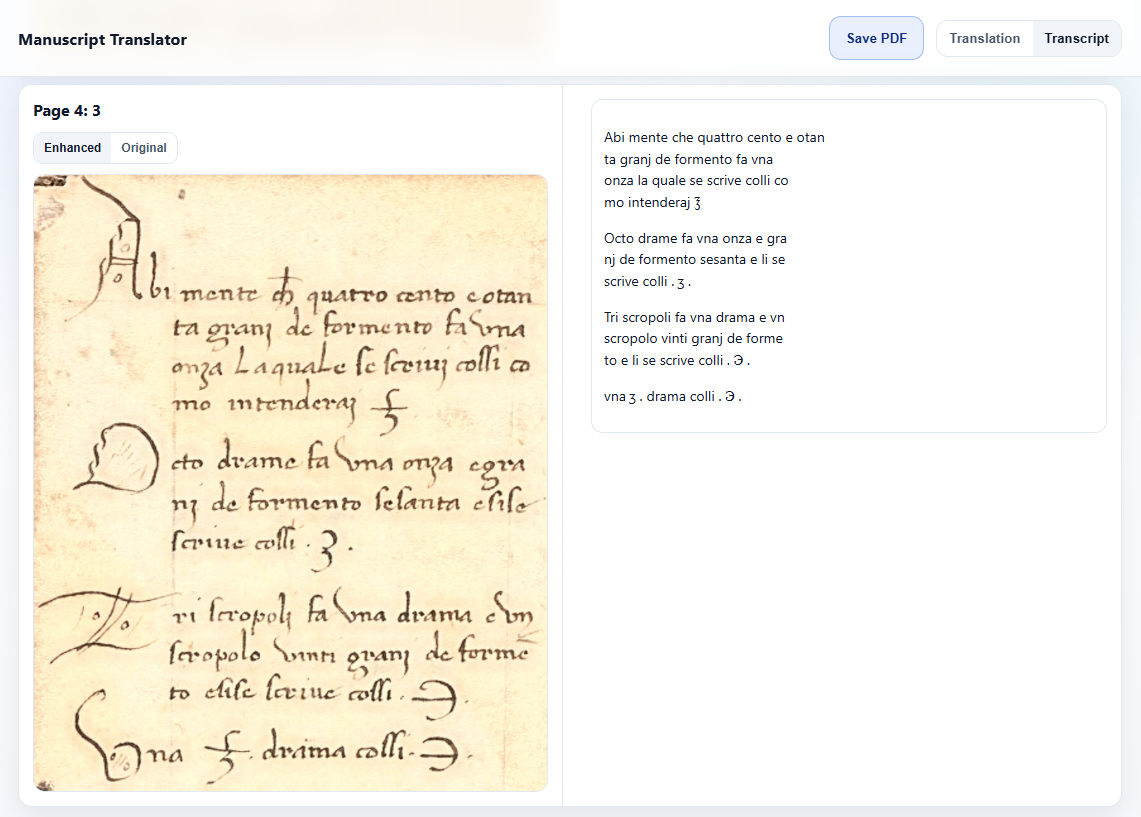
Enhanced text.
For translation, I tried both Gemini 3 Pro and GPT-5.2, choosing the latter due to better adherence to the output format. To align the translation with the pages, the model is instructed to wrap the output corresponding to each page in <page_n></page_n> XML tags, which can be parsed out easily. Another strategy I want to try at some point is to sample outputs from multiple models and have them debate to produce a translation collectively.
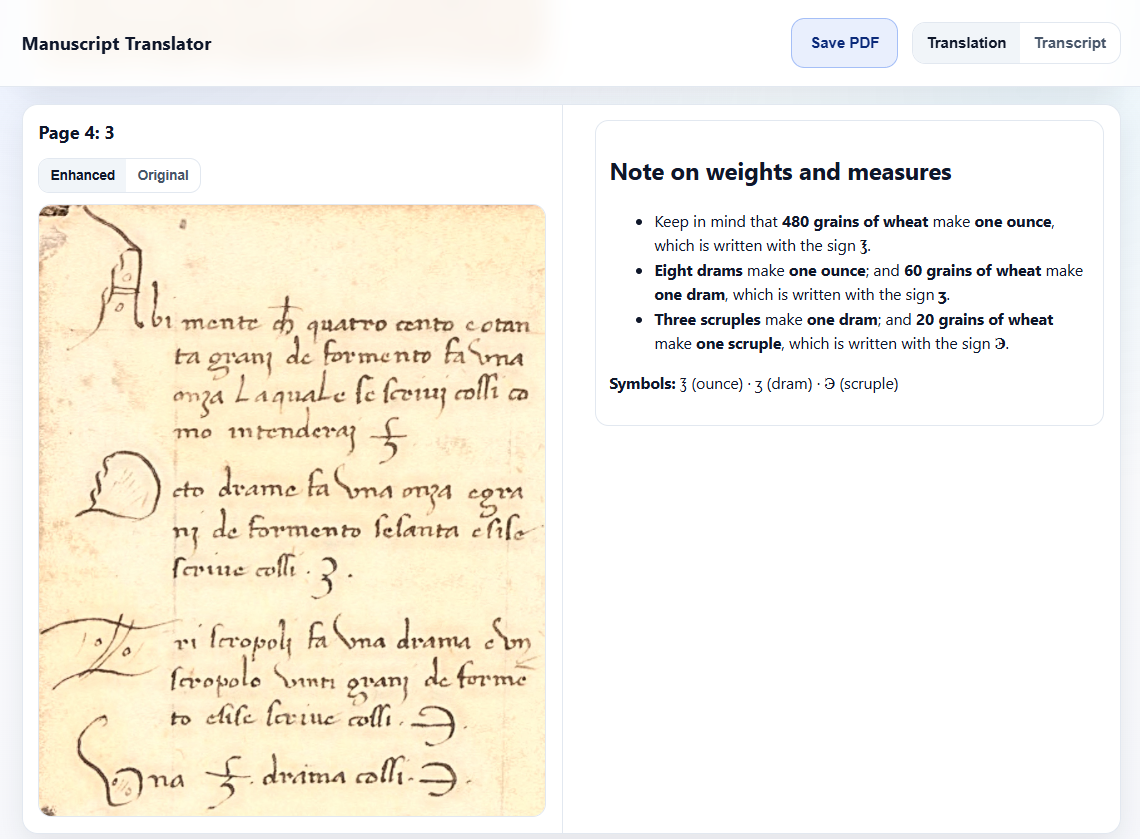
Resulting translation.
As a final touch, I added a button to download the full document with the original images, transcripts, and translations side-by-side as a PDF.

Side-by-side PDF layout.
Anthropology is certainly not my main area of interest, but I do enjoy seeing the progress frontier models are making in fields outside of programming and basic knowledge work. I’m far from an industry veteran (just 22 years old), but I do remember learning about CNNs back when people still cared about MNIST / CIFAR and YOLO was a new thing. We live in extraordinary times and I’m incredibly optimistic about the potential for frontier models in all types of research. Even if the promises of automated researchers or “superintelligence” do not come to pass, the existing models still have so much untapped potential and I expect we’ll see many breakthroughs as adoption increases.
If you want to try it out, the code is available on Github