Today I’m releasing HieroglyphBench, a challenging benchmark that tests how well VLMs can transcribe ancient Egyptian hieroglyphs. You can check out the dataset on Huggingface and the source code on Github.
Given a column of hieroglyphs, models must output the signs they see as Gardiner sign-list codes, in reading order. A Gardiner code names a sign’s type regardless of which way it faces: the owl is G17, the mouth is D21, and the seated man is A1. The results are scored using edit distance against ground-truth transcriptions.
Every reasoning-capable model is run at medium effort. The three open-weight models, Kimi K2.6, MiniMax M3, and Qwen 3.7 Plus, use their official providers to avoid third-party hosting issues.
Many visual understanding benchmarks are nearing saturation and struggle to differentiate between the latest frontier models, despite substantial differences in their capabilities. HieroglyphBench exposes this gap, with the best models (all of which are from the Gemini family) barely scoring 50%. Models from the other labs struggle even more and most do not reach 20%.
Examples


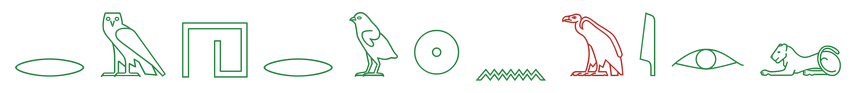



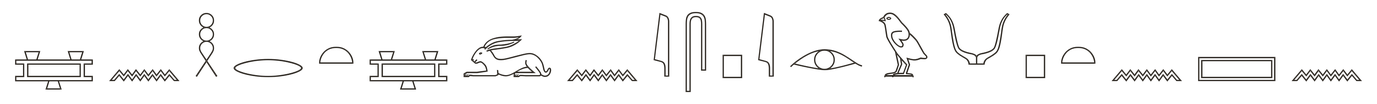
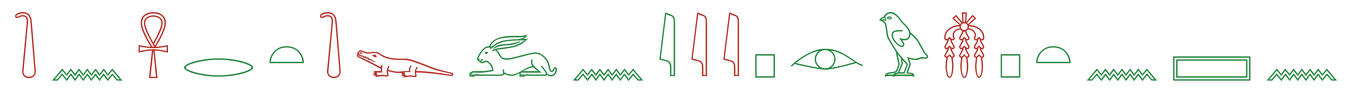

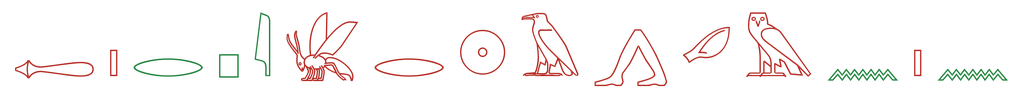


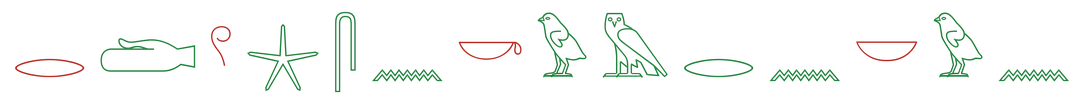
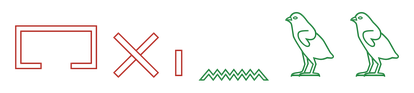
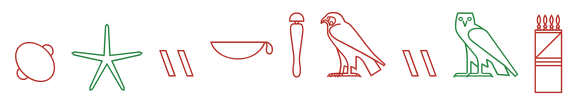
The top models track the column sign by sign and slip mostly on signs that look alike: one bird for another, a reed for a forearm. Lower-scoring models catch an occasional sign but lose the order or fill the gaps with noise.
Dataset construction
The source is the Pyramid of Unas dataset (Morris Franken’s GlyphDataset), built from Alexandre Piankoff’s 1955 photographic plates of the Pyramid Texts in the tomb of the pharaoh Unas during the late 5th Dynasty, around 2350 BCE.
From this, I build column-level inscription items by detecting and splitting columns into chunks. Each chunk is cropped from the original plate photograph using the bounding box of its signs plus padding, and the ground truth is the ordered list of Gardiner codes in that crop. The result was ~200 images, which I then skimmed through manually to find 30 examples for the final dataset. This is enough to keep the noise low (re-running doesn’t move the scores more than ~1%) while also staying cheap enough for me to update the leaderboard as new models are released.
Gathering the data was by far the most time-consuming of this project. I tried scraping a bunch of different sources, but they were all too low quality. I was hoping for some more diversity from different monuments, but I think the current version is good enough for now. If you’re reading this and you know of another high-quality source I could add, please reach out and maybe I’ll be able to add it into a v2!
Scoring
The model returns a JSON array of Gardiner codes, enforced with a strict JSON-schema structured output. From this, I compute two metrics:
- Sign error rate: the Levenshtein distance between the predicted sequence and the ground-truth, divided by the number of ground-truth signs.
- Sign accuracy:
1 − sign error rate, floored at 0, so a prediction with more errors than there are signs scores 0 rather than going negative.
Codes are canonicalized before comparison (G017 -> G17, aa1 -> Aa1) so formatting differences don’t count as errors. Both metrics are computed per inscription and then averaged across the whole eval set, weighting each inscription equally. Random guessing scores ~0, since there are over a thousand glyphs.
Thoughts
Last December, after Gemini 3 was released, I had some fun using it to translate medieval manuscripts. This made me wonder how far the models could be pushed, but I couldn’t find any evaluations online, so it just stayed as a nagging idea in the back of my head. I recently had a bit of time to do more testing and this benchmark is the result. None of the current models are reliable enough yet to be used for serious research, but they’re improving quickly and it seems plausible that they’ll saturate this task within a generation or two. This is very interesting to me because while it is possible labs are training specifically for this task, it seems unlikely and I suspect this is an emergent capability. I plan to track this as new models are released and will update the leaderboard.