This weekend, I will be in attendance at the Nous Research – RL Environments Hackathon, so to prepare I’ve been playing around with Atropos, their new RL framework that we will be using for the event. After failing to find any guides online, I decided to write my own.
Update: I got 2nd place with VR-CLImax, my implementation of Verified Rewards via Completion Likelihood Improvement for improving LLM humor! You can find the code merged into the Atropos repository.
What is Atropos?
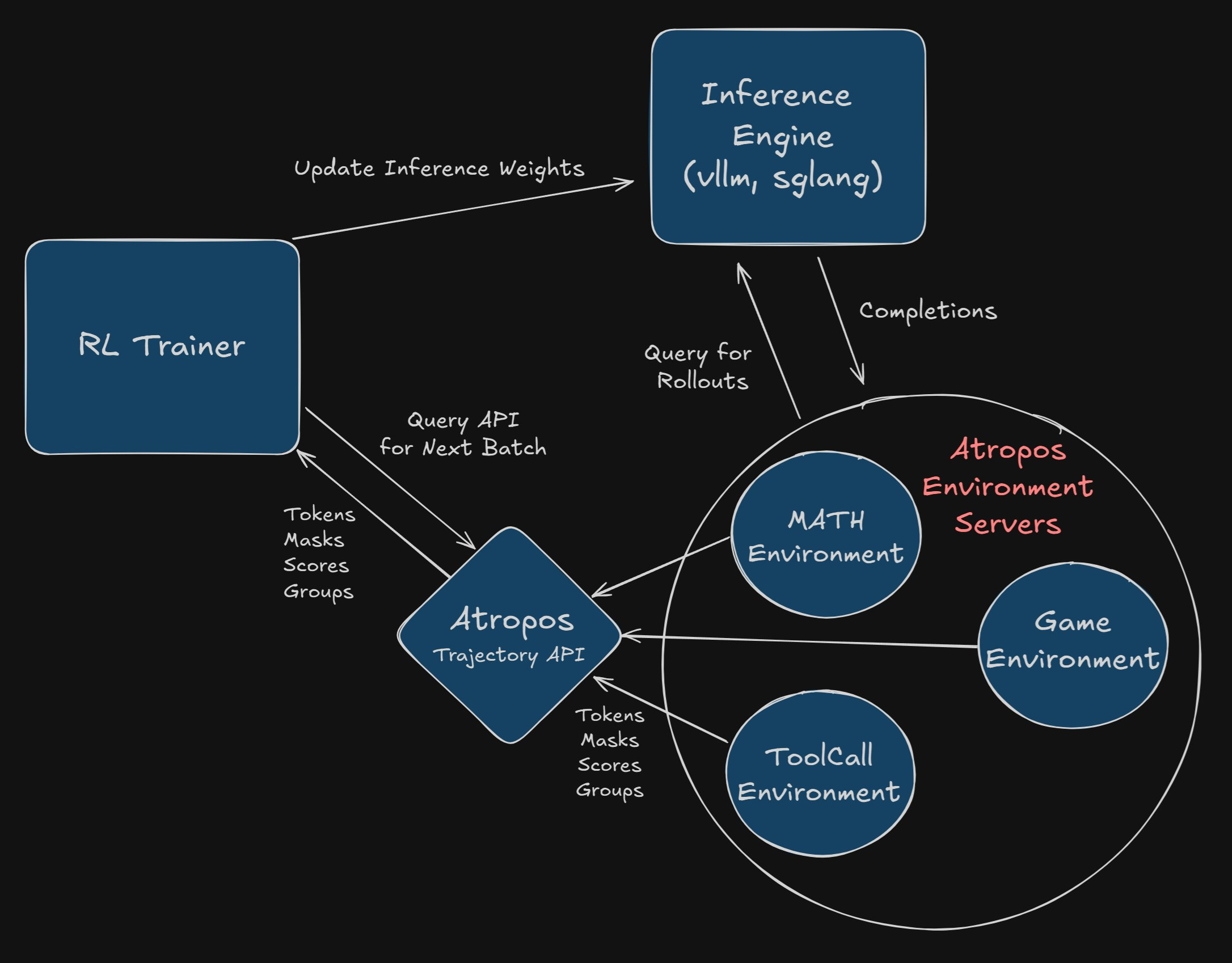
Atropos is a library from Nous Research for performing reinforcement learning with LLMs. It provides a framework for managing environments and collecting rollouts. The training process is broken into four main components (environments, inference, trainer, orchestration), each running separately, enabling them to be distributed across multiple machines.
An example of this might look like training a coding agent, where the training script (handling backpropagation, loss calculations, and weight updates) happens on a powerful GPU cluster, while multiple code execution environments run on smaller CPU nodes. The orchestration server manages the communication between them, collecting rollouts (which could be a code update and its execution results in this example) from the environments and batching them to send to the trainer.
The recommended configuration provided in the repository uses vLLM running inside the trainer process. The environments can then query this vLLM instance when generating rollouts. These rollouts occur asynchronously, with the results passed to the orchestration server after a rollout is complete. Periodically (e.g. every few training steps), the vLLM server is restarted so that it uses the latest set of model weights from the trainer.
Why do we need this?
There are already plenty of reinforcement learning libraries such as TRL, but the structure of Atropos makes it particularly useful for large training setups.
- Scalability and Efficiency: By separating the environments, inference, and training, each component can be scaled independently. For example, you can run numerous environments in parallel on cost-effective CPU instances and maximize the utilization of your inference hardware. This distributed approach and significantly speeds up the data collection and training cycle.
- Flexibility: Atropos allows for heterogeneous hardware setups. Environments can run on different operating systems or hardware configurations without impacting the trainer.
- Real-World Use Cases:
- Coding Agents: As mentioned earlier, training an AI to write or debug code can involve numerous sandboxed execution environments. Atropos can manage these environments, collect the outcomes of code execution (success, failure, errors), and feed this data back to the trainer.
- Game AI: Developing AI for complex games can require simulating many game instances simultaneously. Each game instance acts as an environment, and Atropos can orchestrate the collection of gameplay data (actions, states, rewards).
- Robotics: Training robots often involves physical or simulated environments. Atropos can help manage these diverse environments, allowing for parallel data collection from multiple robots or simulations.
To drive continued performance gains, future models are likely to spend a larger portion of their compute budget on RL instead of pretraining. This will necessitate scalable frameworks.
Environment Setup
Create a python environment and install dependencies:
python -m venv atropos
source atropos/bin/activate
pip install "vllm>=0.8.5" torch transformers datasets wandb tenacity atroposlib pydantic
Code Structure
We’ll go over the GSM8K example from the Atropos repository. At the time of writing, there are a couple of small bugs that you will need to fix if you plan to run them yourself.
In
trainer.py, the wandb variables need to be empty strings and notNoneif you are not using wandb, otherwise the script will error:wandb_project: Optional[str] = Field("", description="Wandb project name") wandb_group: Optional[str] = Field("", description="Wandb group name")Again in
trainer.py, you need to setmodel.config.use_cache = Falseto support the gradient accumulation.
With that out of the way, here are the important files and functions:
gsm8k_environment.py
This script defines the GSM8kEnv class, which is responsible for interacting with the GSM8k dataset, generating prompts, collecting model completions, and scoring them.
Key Components:
GSM8kEnv(BaseEnv):- Inherits from
BaseEnvin theatroposlib. - Manages the GSM8k environment, including data loading, interaction with the LLM server for completions, and scoring.
- Handles wandb logging for metrics like percent correct.
class GSM8kEnv(BaseEnv): name = "gsm8k" def __init__( self, config: BaseEnvConfig, server_configs: List[APIServerConfig], slurm=True, testing=False, ): super().__init__(config, server_configs, slurm, testing) self.percent_correct_buffer = list() self.eval_metrics = list() # Add tracking for wandb visualizations self.rollouts_for_wandb = [] self.completion_lengths = []- Inherits from
config_init():- A class method to define default configurations for the environment (
BaseEnvConfig) and the API server(s) (APIServerConfig) it interacts with. This includes tokenizer name, batch sizes, wandb settings, and model details for the inference server.
@classmethod def config_init(cls) -> Tuple[BaseEnvConfig, List[APIServerConfig]]: env_config = BaseEnvConfig( tokenizer_name="NousResearch/DeepHermes-3-Llama-3-3B-Preview", group_size=8, use_wandb=True, rollout_server_url="http://localhost:8000", total_steps=1000, batch_size=12, steps_per_eval=100, max_token_length=2048, wandb_name="gsm8k", ) server_configs = [ APIServerConfig( model_name="NousResearch/DeepHermes-3-Llama-3-3B-Preview", base_url="http://localhost:9001/v1", # Points to the vLLM server started by trainer.py api_key="x", # Placeholder, as vLLM by default doesn't require an API key num_requests_for_eval=256, ), ] return env_config, server_configs- A class method to define default configurations for the environment (
setup():- Loads and preprocesses the GSM8k dataset (train and test splits).
async def setup(self): self.train = load_dataset("gsm8k", "main", split="train").shuffle(seed=42) test_data = load_dataset("gsm8k", "main", split="test").shuffle(seed=42) self.test = list() for item in test_data: self.test.append( { "question": item["question"], "gold_answer": item["answer"] .split("#")[-1] .strip() .replace(",", ""), } ) self.iter = 0collect_trajectories(item: GSM8kRow):- Takes a data item (question and answer).
- Formats the prompt.
- Sends requests to vLLM to get
ncompletions (rollouts) for the question. - Prepares the data for scoring.
async def collect_trajectories( self, item: GSM8kRow ) -> Tuple[ScoredDataGroup, list[Item]]: user_message = {"role": "user", "content": item["question"]} gold_answer = ( "\boxed{" + item["answer"].split("#")[-1].strip().replace(",", "") + "}" ) chat_completions = await self.server.chat_completion( messages=[{"role": "system", "content": system_prompt}, user_message], n=self.config.group_size, # Number of completions to generate max_tokens=self.config.max_token_length, ) # ... prepares data for scoring ... return to_postprocess, to_backlogscore(rollout_group_data):- Takes a group of rollouts.
- Parses the generated answers and the gold answer using
latex2sympy2_extendedandmath_verify. - Assigns a reward (1.0 for correct, -1.0 for incorrect).
- Tokenizes the messages for the trainer.
- Applies a length penalty if all answers in a group are correct, to encourage conciseness.
- Returns
Noneif all scores are identical (e.g., all correct or all incorrect) to avoid sending uninformative data to the trainer, or if the gold solution is unparseable.
async def score( self, rollout_group_data ) -> Union[Optional[ScoredDataGroup], List[Optional[ScoredDataGroup]]]: # ... parsing and verification logic ... reward = verify(answer_parsed, gold_parsed) # ... tokenization ... scores["scores"].append(1.0 if reward else -1.0) # ... length penalty logic ... if all([scores["scores"][0] == score for score in scores["scores"]]): return None # If all the same, we return None return scoresget_next_item():- Provides the next training item from the dataset.
trainer.py
This script is responsible for the actual model training process. It initializes the model and tokenizer, sets up the optimizer, fetches data batches from the orchestration server (which gets them from gsm8k_environment.py), performs the training steps, and manages the vLLM inference server.
Key Components:
TrainingConfig(BaseModel):- A Pydantic model defining all necessary configurations for training, such as model name, learning rate, batch size, sequence length, device, save paths, and vLLM specific settings.
class TrainingConfig(BaseModel): model_name: str = Field(..., description="Name of the base model to train") lr: float = Field(1e-5, description="Learning rate for the optimizer") training_steps: int = Field(10, description="Number of training steps") batch_size: int = Field(2, description="Batch size for training") # ... other fields ... vllm_port: int = Field(9001, description="Port for the vLLM server") use_wandb: bool = Field(False, description="Whether to use Weights & Biases for logging")register_trainer(config: TrainingConfig):- Sends a POST request to the orchestration server (
http://localhost:8000/register) to register itself, providing its configuration details. This allows the orchestration server to know about the trainer and its requirements.
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=15)) def register_trainer(config: TrainingConfig): requests.post( "http://localhost:8000/register", json={ "wandb_group": config.wandb_group, # ... other registration details ... "num_steps": config.training_steps, }, timeout=10, )- Sends a POST request to the orchestration server (
get_data(batch_size: int, seq_len: int):- Continuously polls the orchestration server (
http://localhost:8000/batch) for new batches of data.
def get_data( batch_size: int, seq_len: int ) -> List[Tuple[List[torch.Tensor], List[torch.Tensor], List[torch.Tensor]]]: batches = [] while True: data = get_batch() # Fetches from http://localhost:8000/batch if data["batch"] is not None: batches.append(pad_data_to_good_offset(data, batch_size)) elif len(batches) > 0: return batches else: time.sleep(1)- Continuously polls the orchestration server (
train(config: TrainingConfig):- Initialization:
- Sets up Weights & Biases (wandb) if configured.
- Loads the tokenizer and model from Hugging Face (
AutoTokenizer,AutoModelForCausalLM). - Sets up the AdamW optimizer.
- Registers the trainer with the orchestration server.
- vLLM Management:
- Launches an initial vLLM server instance as a subprocess using the base model.
- The
vllm_processglobal variable tracks this subprocess.
- Training Loop:
- Iterates for
config.training_steps. - Fetches data using
get_data(). - For each batch:
- Performs a forward pass through the model.
- Calculates the GRPO loss. The loss encourages actions with positive advantages and discourages those with negative advantages.
- Performs backpropagation and optimizer step.
- Logs metrics (loss, learning rate, gradient norm, log probabilities) to the console and wandb.
- vLLM Restart and Checkpointing:
- Periodically (defined by
config.vllm_restart_interval) or on the last step:- Saves a model checkpoint (weights and tokenizer).
- Terminates the current vLLM process.
- Launches a new vLLM process using the newly saved checkpoint, allowing the environment to use the updated model for subsequent rollouts.
- Periodically (defined by
- Iterates for
def train(config: TrainingConfig): global vllm_process # ... Wandb Setup, Model & Optimizer Init ... register_trainer(config) # Init vLLM with base model vllm_command = [ "python", "-m", "vllm.entrypoints.openai.api_server", "--model", config.model_name, # ... other vLLM args ... ] vllm_process = subprocess.Popen(vllm_command) for step in range(config.training_steps): # ... fetch data ... # ... training step, loss calculation, optimizer.step() ... if (step + 1) % config.vllm_restart_interval == 0 or step == config.training_steps - 1: checkpoint_path = os.path.join(config.save_path, f"step_{step+1}") model.save_pretrained(checkpoint_path) tokenizer.save_pretrained(checkpoint_path) # Terminate existing vLLM if vllm_process: vllm_process.terminate() vllm_process.wait() # Launch new vLLM with updated model updated_vllm_command = [ "python", "-m", "vllm.entrypoints.openai.api_server", "--model", checkpoint_path, # Use the new checkpoint # ... other vLLM args ... ] vllm_process = subprocess.Popen(updated_vllm_command) # ... final save and cleanup ...- Initialization:
Training Process
Once you have installed the dependencies, download the environment and training scripts (you might need to rename them), then complete the steps below:
Start Orchestration Server: Open a terminal, activate your environment, and run:
mkdir empty cd empty run-apiThis server listens on
http://localhost:8000and coordinates between the environment and trainer. We’re doing this inside an empty folder because Atropos listens for files changes for some reason and will restart the server every time a checkpoint is saved, breaking the training process.Start Environment: Open another terminal, activate the environment, and run:
python gsm8k_environment.py serve --slurm falseThe environment will attempt to connect to the orchestration server. Initially, it might wait if the trainer hasn’t registered yet.
Start Trainer: Open a third terminal, activate the environment, and run:
python trainer.py- The
trainer.pyscript will:- Initialize a model (e.g., “Qwen/Qwen2.5-1.5B-Instruct”).
- Start a vLLM server instance using this base model on a specified port (default 9001).
- Register itself with the orchestration server.
- Once the trainer registers, the environment(s) will start generating rollouts using the vLLM server managed by the trainer.
- The environment sends scored rollouts to the orchestration server.
- The trainer fetches these rollouts from the orchestration server, performs training steps, and updates its model weights.
- Periodically, the trainer saves a checkpoint and restarts the vLLM server with the updated model weights, allowing the environment to benefit from the training progress.
- The
This setup allows for a decoupled system where data generation (environment) and model training (trainer) can happen independently and potentially on different hardware, coordinated by the orchestration server.
The project is actively being developed, so I would not be surprised if this guide quickly becomes outdated. Hopefully it’s at least useful for someone else at the hackathon. See you all there!
Twitter: @JakeABoggs